








There is an idea to use a “section recommendation” feature to help editors write articles by suggesting possible sections to be added. But it is possible that its recommendations inadvertently increase gender bias. Here’s how we could deal with it.
A Section Recommender for Wikipedia
An experimental development, the section recommendation feature’s main goal is to make it easier for newcomers to start and expand Wikipedia articles. It is a machine learning tool that analyses existing Wikipedia articles and pulls out statistical data, like what type of “sections” or “subheadings” exist in articles about living people, battles or cities. It then uses these statistical records to recommend to the user categories they might want to add to the article they are editing. So if you are editing an article about a town, it might suggest section titles such as “Government and law”, “Demographics” or “Twin towns – sister cities”, all three very common sections in city articles on Wikipedia.
Reinforcing gender bias
One major issue in the process is that when it comes to Wikipedia biographies, men are more likely to have sections such as “Career” and “Awards and honors”, while women are more likely to have sections such as “Personal life” and “Family”. This is an existing social, systemic bias on Wikipedia that is perpetuated. Part of it is a spillover from traditional sources – historical documents, books and journals that are predominantly about men.
The section recommender feature is likely to quickly “learn” this and will start, while helping editors improve article quality in many cases, increasing the systemic bias in which men and women are portrayed on Wikipedia.
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
_2.jpg){kind=link}
{kind=link}
.jpg){kind=link}
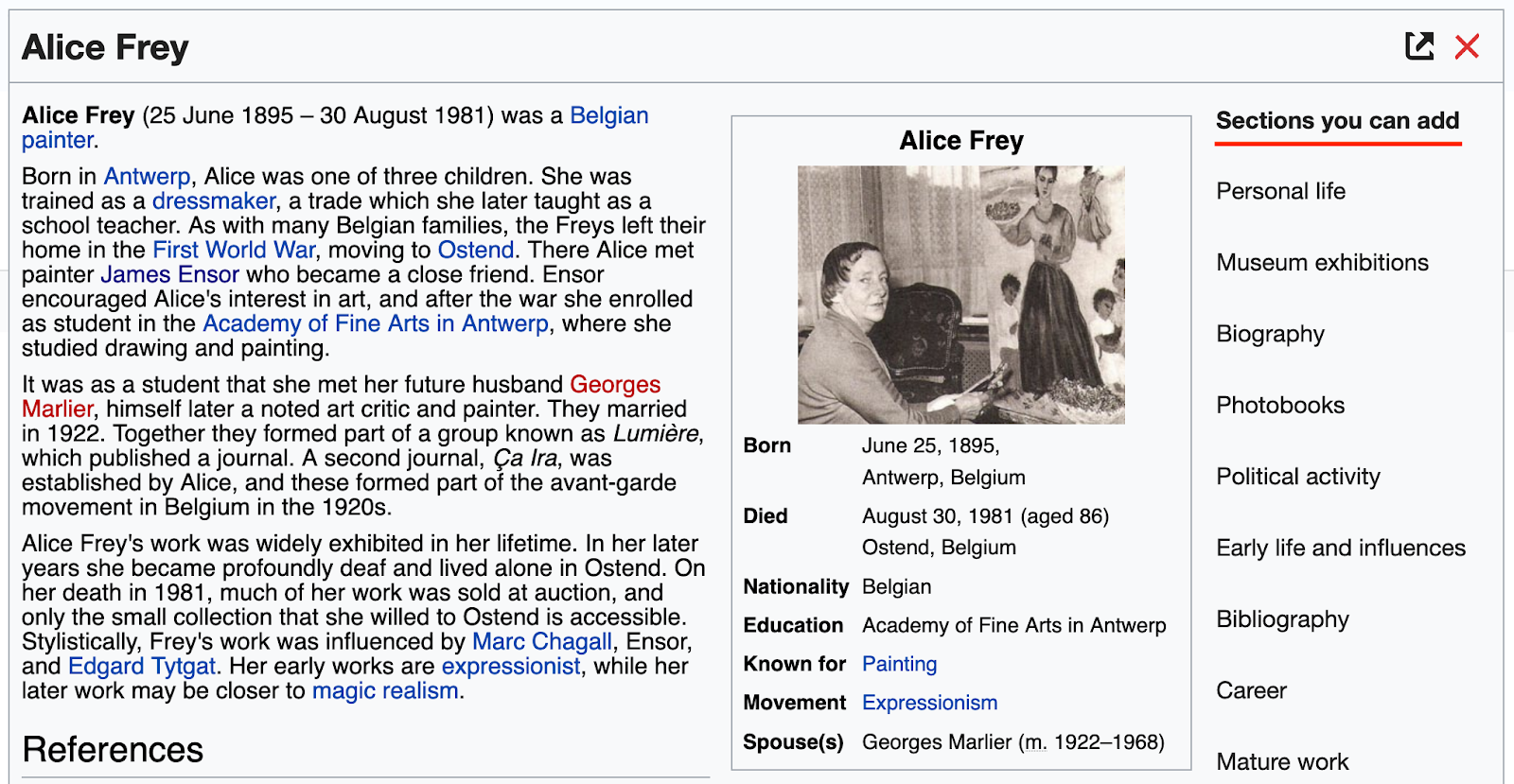
Could algorithmically-generated section recommendations inadvertently increase gender bias in biographies of women? (risk scenario A: Reinforcing existing bias.) Text from the English Wikipedia article about “Alice Frey”, CC BY-SA 3.0. Image by unknown, used in the article under fair use. Mockup by Wikimedia Foundation, CC BY-SA 3.0.
{kind=link}
Identifying risk, then addressing it
Once the developers and users recognise this, there are usually simple technical fixes. In this case it would be to set up the system to not distinguish between biographies about women and men, for instance. It would then suggest sections, such as “Career” and “Family” to all biographies.
In order to recognise such biases in advance, we need to work on risk scenarios – short hypothetical situations about AI-powered products and their results in a specific environment. Then we need to change the process of developing AI-powered products, and then the design of the products themselves. It is important to not only change the product, but also the actual development process, in order to avoid similar gaps in the future.
Openness, because no developer can think of all risks
Much of the public debate on ethical AI has revolved around generalprinciples like fairness, transparency and accountability. Articulating the principles that underlie ethical AI is an important step. But technology companies also need practical guidance on how to apply those principles when they develop products based on AI, so that they can identify major risks and make informed decisions.
One thing that makes it so hard to recognise biases and unintended negative consequences is that they are part of our culture, of how we grew up and how we talk and think. We don’t see them until someone points it out to us. It would be foolish to assume that even the most experienced and well-meaning developers and providers can catch most of them.
In our mind, communities, especially marginalised ones, know better than regulators and developers what content and consequences of a tool or resource are truly harmful to them. This is why we must make sure our systems are as open and transparent as possible. We must give every individual and every community a chance to see how ML/AI algorithms work and even a way to toy with them. And then when they signal to us that something is not right, we should have solid review and redesign systems in place. And while it is hard to imagine that a private company could ever be as open and transparent as a non-for-profit such as Wikimedia, we could and should very well demand this from the government and public services.
Recommended reading
- Designing ethically with AI: How Wikimedia can harness machine learning in a responsible and human-centered way
- Ethical and human centered AI
A miniseries on machine learning tools
Machine Learning and AI technologies have the potential to benefit free knowledge and improve access to trustworthy information. But they also come with significant risks. Wikimedia is building tools and services around these technologies with the main goal of helping volunteer editors in their work on free knowledge projects. But we strive to be as human centered and open as possible in this process. This is a miniseries of blog posts that will present tools that Wikimedia concepts, develops and uses, the unexpected and sometimes undesired results and how we try to mitigate them. Today, we present ORES, a service meant to recognise vandalism.