








{kind=link}
{kind=link}
_2.jpg){kind=link}
{kind=link}
.jpg){kind=link}
.jpg){kind=link}
{kind=link}
There is a machine learning service available to interested Wikimedia projects and communities called ORES. It aims to recognise if an edit, for instance on Wikipedia, is damaging or done in good faith. Of course, false predictions cannot be avoided and thus remain a major risk. Here’s how we try to handle it.
ORES: A system designed to help detect vandalism
ORES (Objective Revision Evaluation Service) is a web service and API that provides machine learning as a service for Wikimedia projects and is designed to help automate critical wiki-work – for example, vandalism detection and removal. In practice it aims to help human editors, in this case patrollers (volunteers who review others’ edits), identify potentially damaging edits. Importantly, the decision whether an edit is kept or reverted isn’t made by the algorithm, it always remains with the human patroller.
In order to make a prediction about edits, ORES looks at the edit history across Wikipedia and calculates two general types of scores – “edit quality” and “article quality”. In this post, we will focus on the former for the sake of simplicity.
“Edit Quality” Scores
One of the most critical concerns about Wikimedia’s open projects is the review of potentially damaging contributions. There’s also a need to identify good-faith contributors – who are inadvertently causing damage – and offer them support.
In its most basic functionality, the ORES machine looks at the history of edits on Wikipedia and assumes that most damaging edits have been reverted rather quickly by human patrollers, whereas good faith edits stay untouched longer. Based on this, ORES gathers statistical data on edits, which it then groups into “features” – things like “curse words added”, “length of edit”, “citation provided”, or “repeated words”.
These features, the system assumes, help assess whether an edit is made in good faith or damaging. ORES makes a prediction and presents it to a human for further consideration. It is important to emphasise again and again what such machines do: predictions based on assumptions. The results might change considerably if were to use different features, which takes us to the next important functionality: feature injection.
Features: The numbers that let machines recognise correlations
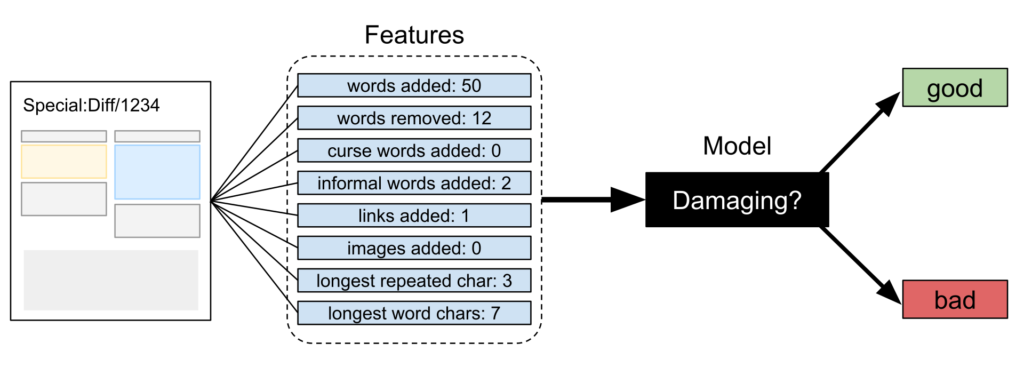
In the pictured example, features of an edit are measured (e.g. “words added” and “curse words added”), because under some circumstances, they correlate with damaging edits. A machine learning algorithm can use features like these to identify the patterns that correlate with vandalism and other types of damage in order to do something useful—like help with counter-vandalism work.
Features are how machines see the world. If some characteristic of an edit suggests that the edit is vandalism, but that characteristic is not captured in any of the features that are measured and provided to a machine learning algorithm, then the algorithm cannot learn any patterns related to it.
Feature Injection
Features depend largely on human input and data available. They are thus, just like data and human history, prone to biases. This is why it is crucial that we are open and transparent about how a result was determined and which features were decisive. Wikimedia offers a functionality that allows us to ask ORES which features it used when it made a prediction about an edit. For instance, we can check which features it used when assessing revision number 21312312 of the article French Renaissance on English Wikipedia.
We can go even a step further. ORES lets us toy around with the assessment above by adding and removing features as we see fit. We can either use authentic data from Wikipedia or add synthetic data we came up with in order to see how that would influence the result. What if the article was properly referenced? What if the vocabulary contained more sophisticated terms? We can test those things on an actual article.
Feature Injection for Everyone
To be ethical and human centred, machine learning systems must be open and offer people a way to test them, to figure out how they work and react. Not because of the things we know, but because of the things we don’t always immediately realise. We have a gender bias on Wikipedia. Users who identify as female have reported that their edits were seen more critically than when they didn’t report their gender. Biographies about women are fewer and shorter. This alone is enough for a machine learning tool to pick up biases and magnify them and it might be very hard for us to recognise this. Similar biases exist with race, language, age and many other categories. And that is precisely why we need systems that are transparent. Ideally they will be open to everyone, and ideally not only on Wikipedia. No, this won’t solve the issue of bias, but it might limit it. And it will give civil society and researchers a tool to counter negative developments.
A miniseries on machine learning tools: Machine Learning and Artificial Intelligence technologies have the potential to benefit free knowledge and improve access to trustworthy information. But they also come with significant risks. Wikimedia is building tools and services around these technologies with the main goal of helping volunteer editors in their work on free knowledge projects. But we strive to be as human centred and open as possible in this process. This is a miniseries of blog posts that will present tools that Wikimedia develops and uses, the unexpected and sometimes undesired results and how we try to mitigate them.